Extracting text from images for beginners using nodejs

In this blog, we are going to learn about OCR and write a small node JS program that actually does OCR.
**Table of Contents - **
1. Information on OCR.
2. Things you need.
3. Setting up your node JS project and installing the packages to perform OCR.
4. Writing a simple beginner friendly program (Single Worker).
5. Writing an advanced program (Multiple Workers).
Before you read - I really want you to try this yourself after you're done reading.
Ever wondered how Instagram or a tech company adds a pop or link to images that contain words like Vaccine or Corona? Or how the Google extracts texts from the image in their Google translation.
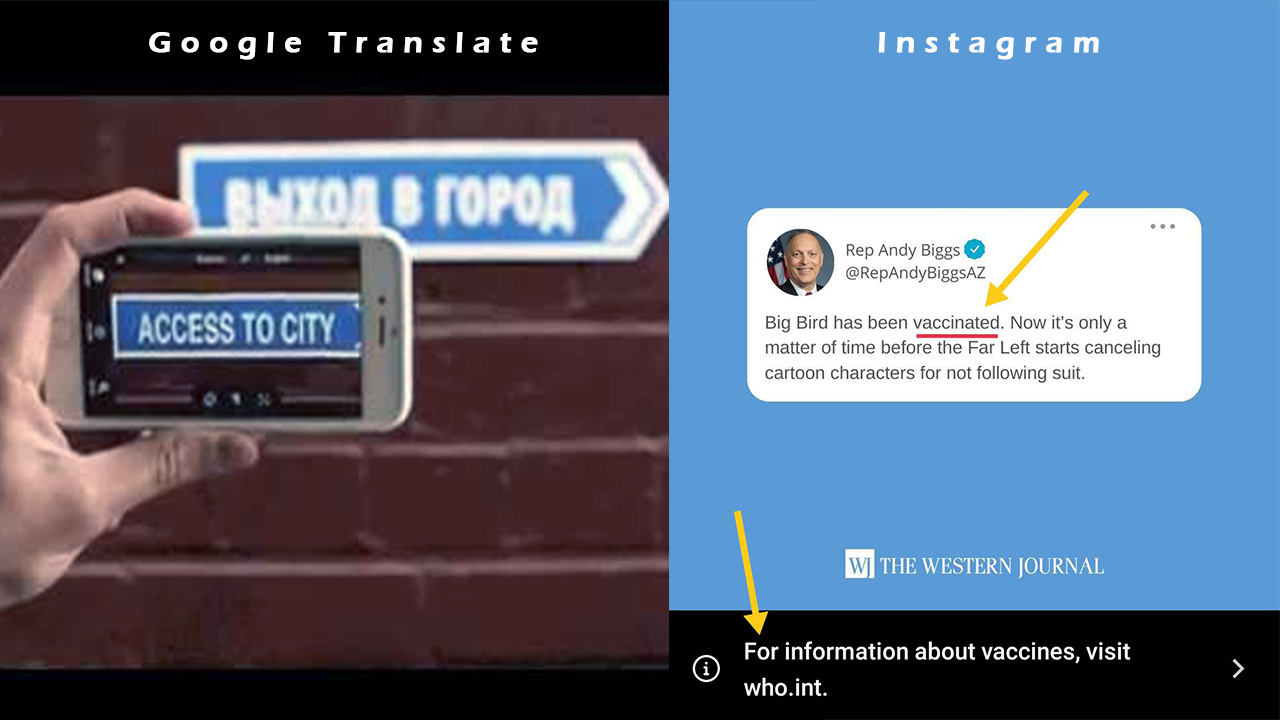
Well this is done by OCR. ⬆😀
What Actually is OCR?
Literally, OCR stands for Optical Character Recognition or Optical Character Reader. This is a common technology for recognizing text in images, such as scanned documents and photos. OCR technology is used to convert practically any type of image containing written text (typewritten, handwritten or printed) into machine-readable text data.
What is OCR Used For? Popular usage cases for OCR.
Probably the most well-known use case for OCR is converting printed paper documents into machine-readable text documents. Once a scanned paper document is processed by the OCR, the text of the document can be modified using word processing software such as:
Microsoft Word
Google Docs
Others -
Google Translate
Adobe programs.
Now that you know what OCR is, why not make a **simple program ** that actually does OCR.
Things you need before starting.
Ignore step 3 now as we would Install it later.
Steps to Create your project.
Make a folder.
Open your terminal and change directory to the folder you have just created.
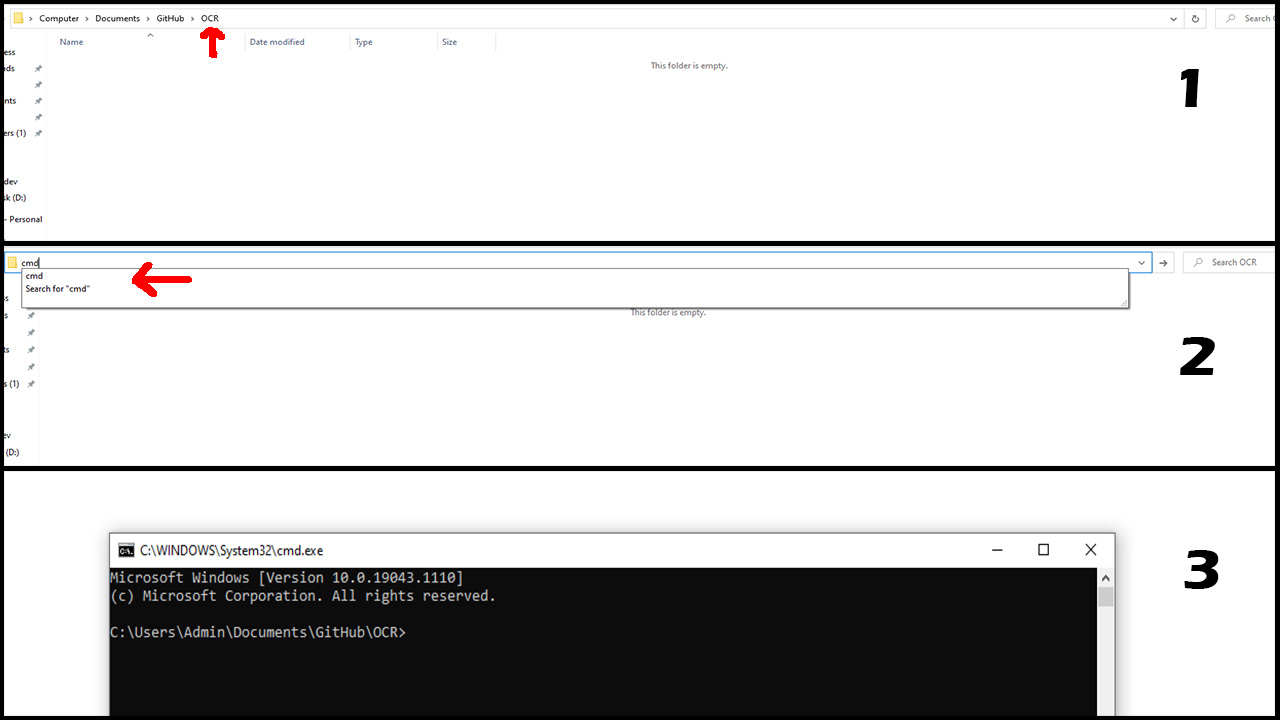
3 - Now in the terminal, write npm init and fill in the project details.
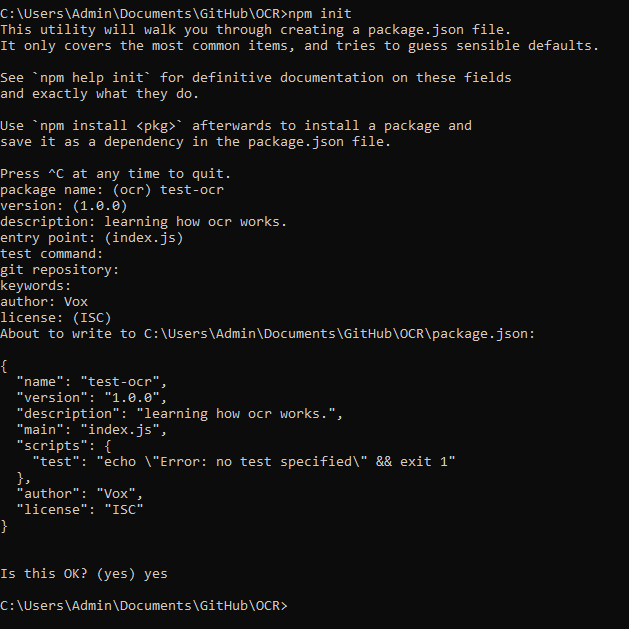
Step 3 helped you set up a package.json file which is responsible for installing dependencies, run scripts, and identify the entry point to our project.. well, now our project folder is ready.
4 - In the same terminal write npm i tesseract.js (⚠ This is an Important step.)
Step 4 helped you install all the packages needed for OCR.
Are you ready to code? 😀
Open your folder in the Visual Studio Code.
Programming 🔥.
Using Single Worker.
- Create an entry point file with the name your
package.jsonhas. In my case itsindex.jswhich is default.
From here down, read the comments within the code blocks to understand the code.
/**
* 👇 Requiring the function from the tesseract module to spawn a worker.
*/
const { createWorker } = require("tesseract.js");
/**
* 👇 Basically this is a child process spawned from fork method.
*/
const worker = createWorker();
/**
* 👇 Self-executing anonymous function.
*/
(async () => {
const start = new Date();
/**
* 👇 Loading the worker scripts from the tesseract core.
*/
await worker.load();
/**
* Loads traineddata from cache or download traineddata from remote
* Link to install traineddata https://github.com/tesseract-ocr/tessdata
* You can train your own custom data but thats for another blog.
* 👇
*/
await worker.loadLanguage("eng");
/**
* 👇 Initializes the Tesseract API, make sure it is ready for doing OCR tasks.
*/
await worker.initialize("eng");
console.log(
"Starting recognition process.",
"\n_________________________________\n"
);
/**
* Using destructuring assignment and
* calling worker.recognize(image, options, jobId) on it which is a promise.
* If the promise resolves you get the text from the image.
*/
const {
data: { text },
} = await worker.recognize("https://i.imgur.com/LmFPK8Nh.jpg");
console.log(text, "\n_________________________________\n");
const stop = new Date();
let s = (stop - start) / 1000;
console.log(`Time Taken - ${s}\n\n`);
/**
* Terminating the worker to release the allocated ram.
*/
await worker.terminate();
return;
})();
/**
* This called a self-executing anonymous function.
*
* (async () => {
* console.log('Hello World!');
* })();
*
*/
if you are wondering what is const { data: { text }, } = //promise. This is called as destructuring assignment syntax in JavaScript. here
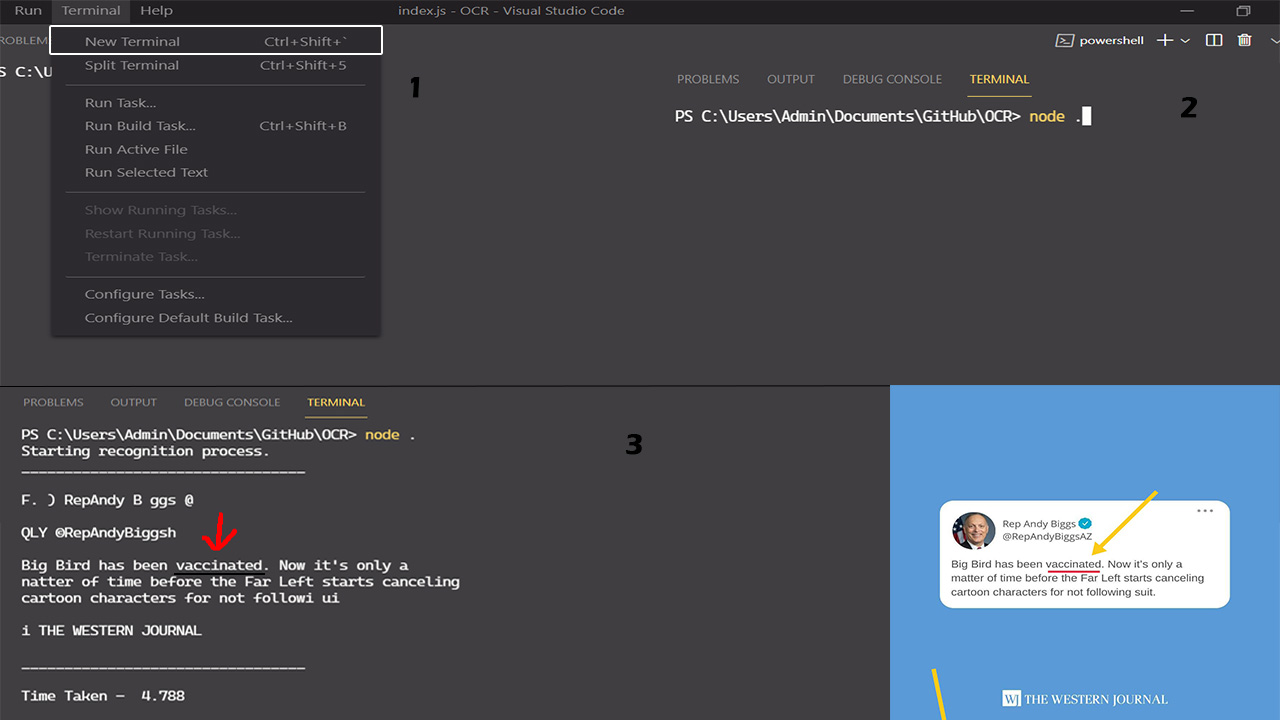
One Request that uses a Single worker
Two Requests that uses a Single worker
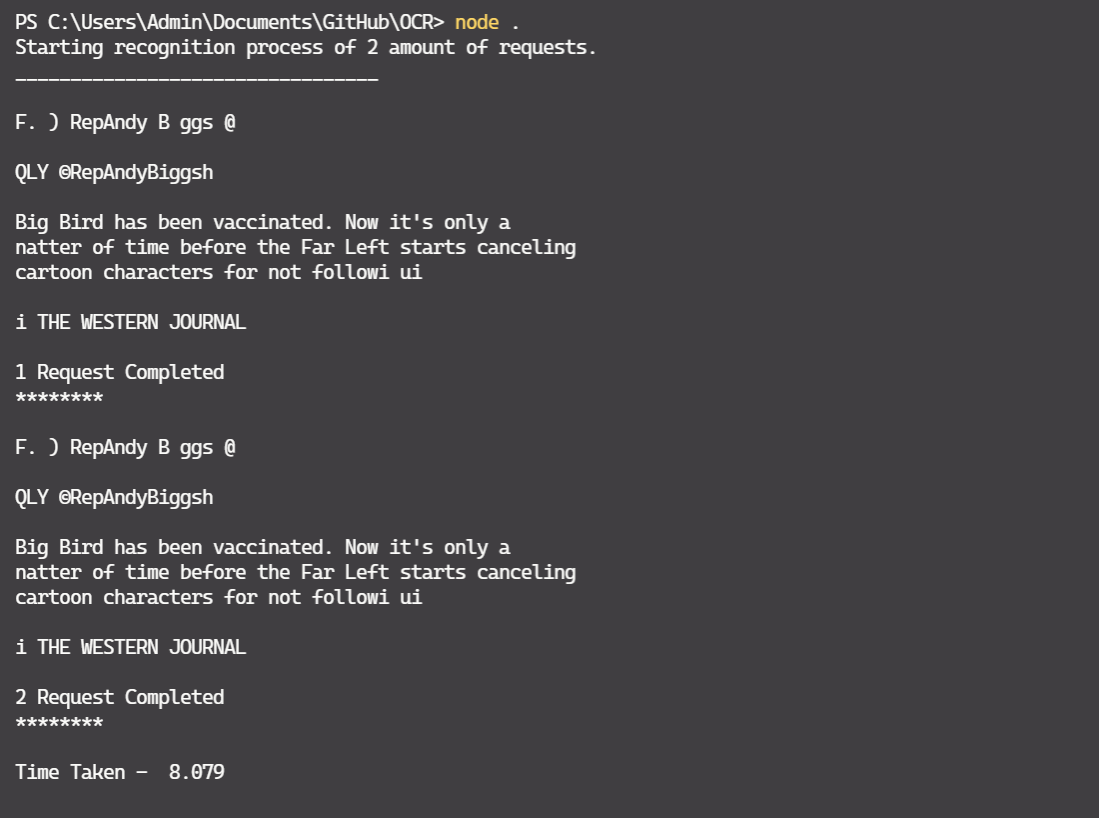
You saw the way that Tesseract works. The above code uses a single child process to perform OCR. But a single worker is slowwwww. Yeaaah... We can increase the number of workers to speed up the process, so we move on to the advanced program.
Using Multiple Workers.
Let's say you have a website that does this OCR. If several users requests for OCR at once, then our Single worker would be really slow. Single worker takes roughly around 4s for a recognition => 4 * 3 = 12s. For 3 recognitions it would roughly take 12s which is really slow. My current code logic just does all the 3 job in just below 2s (Not shown in this blog).
To deal with this kind of situations Tesseract has a pool of workers called as scheduler in which you can create and add workers to it. The program automatically allocates jobs to IDLE workers and that is how it could be done faster.
Example -
/**
* 👇 Requiring the function from the tesseract module to spawn a worker.
*/
const { createWorker, createScheduler } = require("tesseract.js");
/**
* Creating the scheduler which is acutally a worker pool.
*/
const scheduler = createScheduler();
async function CreateMultipleWorkers(amount = 1) {
for (let i = 0; i < amount; i++) {
/**
* 👇 Basically this is a child process spawned from fork method.
*/
const worker = createWorker();
await worker.load();
await worker.loadLanguage("eng");
await worker.initialize("eng");
scheduler.addWorker(worker);
}
console.log(
`${scheduler.getNumWorkers()} numbers of workers in the scheduler.`
);
}
/**
* 👇 Self-executing anonymous function.
*/
(async () => {
const start = new Date();
/**
* It is advised to create workers with the same amount of cores the cpu has.
* OCR is actually a CPU intensive process.
*/
await CreateMultipleWorkers(2);
let recognitions = [];
for (let i = 0; i < 2; i++) {
/**
* calling scheduler.addJob(image, options, jobId)
* Adds the recognition job to the idle worker.
*/
recognitions.push(
scheduler.addJob("recognize", "https://i.imgur.com/LmFPK8Nh.jpg")
);
}
console.log(
`Starting recognition process of ${recognitions.length} amount of requests.`,
"\n_________________________________\n"
);
let res = await Promise.allSettled(recognitions);
for (let j = 0; j < 2; j++) {
const {
value: {
data: { text },
},
} = res[j];
console.log(text, `\n${j + 1} Request Completed\n________\n`);
}
const stop = new Date();
let s = (stop - start) / 1000;
console.log(`Time Taken - ${s}\n\n`);
return;
})();
Using the pool of workers, we could achieve OCR on 2 images in 5s.
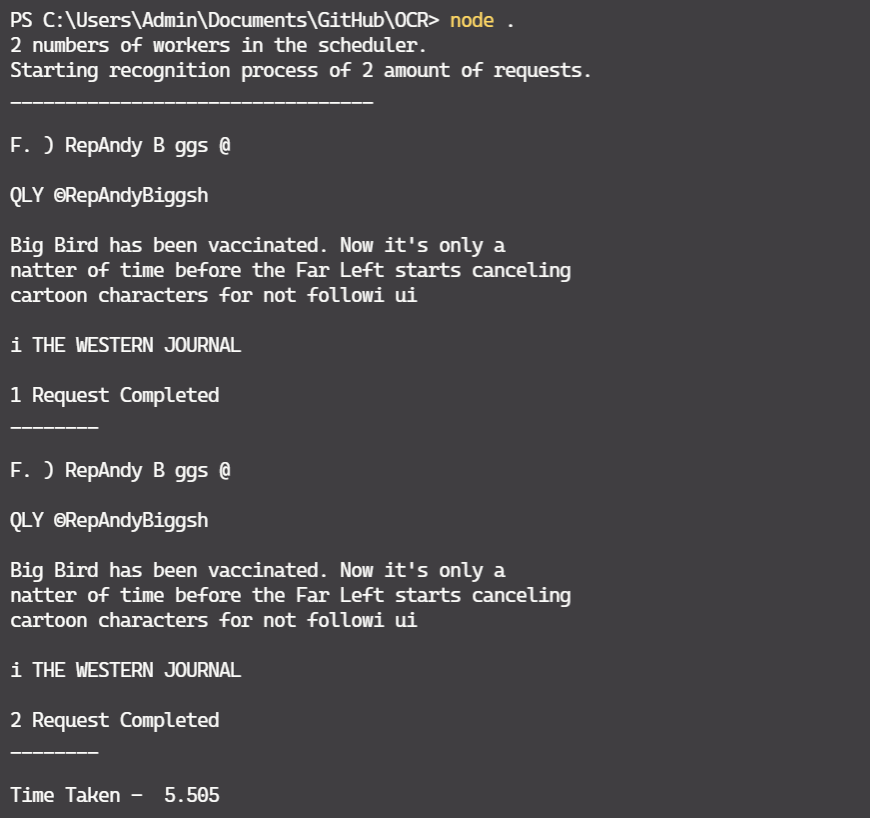
Wohoo!! You have now successfully learnt how to perform OCR using node js. I'll write some more advance code and real implementations if this blog gets some good amount of reach.
Finally
Tesseract.js is a powerful library that helps you perform OCR in node js by various methods.
If you want to increase the recognition speed or read just a specific part of an image then you could use rectangles.
Rectangle is an object to specify the regions you want to recognized in the image, should contain top, left, width and height, see example below.
rectangle: { top: 0, left: 0, width: 100, height: 100 },
Read more about the various methods and modes provided by tesseract.js %[https://github.com/naptha/tesseract.js/blob/master/docs/api.md].
This was my first ever blog. I tried my best to explain, show some love 😀.
Thank you for reading.
Written by: Syed Abdul Rahman (github)


